|
|
| (9 intermediate revisions by the same user not shown) |
| Line 147: |
Line 147: |
| | * In some cases, the equality still holds even if we discard something (upside). This motivates our exploration of the concept of sufficient statistics. | | * In some cases, the equality still holds even if we discard something (upside). This motivates our exploration of the concept of sufficient statistics. |
| | | | |
| − | == Sufficient Statistics == | + | === Sufficient Statistics === |
| | Given a family of distributions <math>\{f_\theta\left(x\right)\}</math> indexed by a parameter <math>\theta</math>. If <math>X</math> is a sample from <math>f_\theta</math>, and <math>T\left(X\right)</math> is any statistic, then we get the Markov chain: | | Given a family of distributions <math>\{f_\theta\left(x\right)\}</math> indexed by a parameter <math>\theta</math>. If <math>X</math> is a sample from <math>f_\theta</math>, and <math>T\left(X\right)</math> is any statistic, then we get the Markov chain: |
| | | | |
| Line 226: |
Line 226: |
| | \end{align}</math>|{{EquationRef|36}}}} | | \end{align}</math>|{{EquationRef|36}}}} |
| | | | |
| − | Since <math>X\rightarrow Y \rightarrow \hat{X}</math> is a Markov chain, we get ''Fano's Inequality'': | + | Since <math>X\rightarrow Y \rightarrow \hat{X}</math> is a Markov chain, as seen in Figs. 3 and 4, we get ''Fano's Inequality'': |
| | | | |
| | {{NumBlk|::|<math>H\left(X\mid Y\right) \leq H\left(X\mid \hat{X}\right) \leq H\left(P_e\right) + P_e\cdot \log_2\left|\chi\right| </math>|{{EquationRef|37}}}} | | {{NumBlk|::|<math>H\left(X\mid Y\right) \leq H\left(X\mid \hat{X}\right) \leq H\left(P_e\right) + P_e\cdot \log_2\left|\chi\right| </math>|{{EquationRef|37}}}} |
| Line 241: |
Line 241: |
| | \end{align}</math>|{{EquationRef|39}}}} | | \end{align}</math>|{{EquationRef|39}}}} |
| | | | |
| | + | [[File:Fanos Inequality.png|thumb|400px|Figure 4: A Venn diagram visualizing <math>X\rightarrow Y\rightarrow \hat{X}</math>.]] |
| | We can further recognize that for <math>E=1</math>, or equivalently when <math>\hat{X}\neq X</math>, we know that <math>\hat{X}</math> is not equal to the actual value of <math>X</math>, thus reducing the possible values of <math>X</math> from <math>\left|\chi\right|</math> to <math>\left|\chi\right|-1</math>, thus: | | We can further recognize that for <math>E=1</math>, or equivalently when <math>\hat{X}\neq X</math>, we know that <math>\hat{X}</math> is not equal to the actual value of <math>X</math>, thus reducing the possible values of <math>X</math> from <math>\left|\chi\right|</math> to <math>\left|\chi\right|-1</math>, thus: |
| | | | |
| Line 252: |
Line 253: |
| | | | |
| | {{NumBlk|::|<math>P_e \geq \frac{H\left(X\right) - I\left(X;Y\right) - 1}{\log_2\left(\left|\chi\right|-1\right)}</math>|{{EquationRef|42}}}} | | {{NumBlk|::|<math>P_e \geq \frac{H\left(X\right) - I\left(X;Y\right) - 1}{\log_2\left(\left|\chi\right|-1\right)}</math>|{{EquationRef|42}}}} |
| | + | |
| | + | Thus, Fano's inequality leads to a lower bound on the probability of error, for any decoding function <math>\hat{X}=g\left(Y\right)</math>, and it depends on the mutual information <math>I\left(X;Y\right)</math>, or how much information about <math>X</math> is contained in <math>Y</math>, and the size of the alphabet <math>\left|\chi\right|</math>. Thus, to reduce the lower bound of <math>P_e</math>, we should minimize <math>H\left(X\mid Y\right)</math>, or equivalently maximize <math>I\left(X;Y\right)</math>, as expected. |
| | + | |
| | + | {{Note|161-A4.1 '''Activity A4.1''' The Data Processing Inequality and Fano's Inequality -- This activity introduces the concept of information loss and the error probabilities associated with entropy and mutual information.|reminder}} |
| | + | |
| | + | == Sources == |
| | + | * Yao Xie's [https://www2.isye.gatech.edu/~yxie77/ece587/Lecture4.pdf lecture] on Data Processing Inequality. |
Entropy Chain Rule

Figure 1: Entropy visualization for two random variables using Venn diagrams.
As we increase the number of random variables we are dealing with, it is important to understand how this increase affects entropy. We have previously shown that for two random variables  and
and  :
:
-
 |
|
(1)
|
We can use Venn diagrams to visualize these relationships, as seen in Fig. 1. For three random variables , , and  :
:
-
 |
|
(2)
|
In general:
-
 |
|
(3)
|
Conditional Mutual Information
Conditional mutual information is defined as the expected value of the mutual information of two random variables given the value of a third random variable, and for three random variables , , and , it is defined as:
-
 |
|
(4)
|
We can rewrite the definition of conditional mutual information as:
-
 |
|
(5)
|
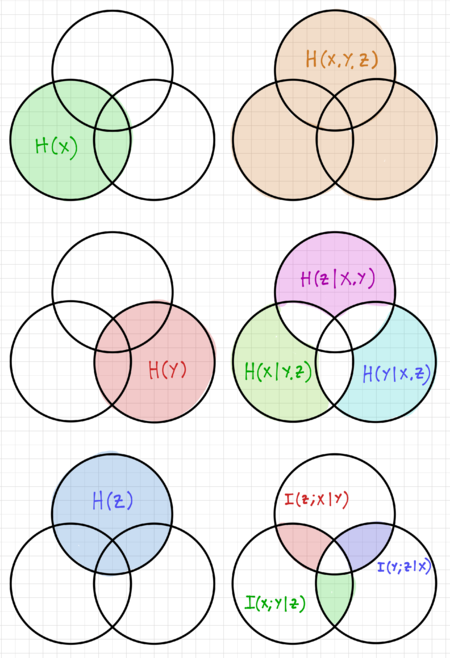
Figure 2: Entropy visualization for three random variables using Venn diagrams.
We can visualize this relationship using the Venn diagrams in Fig. 2. Compare this to our expression for the mutual information of two random variables and :
-
 |
|
(6)
|
Chain Rule for Mutual Information
For random variables and :
-
 |
|
(7)
|
And for random variables , and :
-
 |
|
(8)
|
We can then express the conditional mutual information as:
-
 |
|
(9)
|
Rearranging, we then obtain the chain rule for mutual information:
-
 |
|
(10)
|
Thus, we can extend this for additional random variables:
-
 |
|
(11)
|
In general:
-
 |
|
(12)
|
Markovity
A Markov Chain is a random process that describes a sequence of possible events where the probability of each event depends only on the outcome of the previous event. Thus, we say that  is a Markov chain in this order, denoted as:
is a Markov chain in this order, denoted as:
-
 |
|
(13)
|
If we can write:
-
 |
|
(14)
|
Or in a more compact form:
-
 |
|
(15)
|
We can use Markov chains to model how a signal is corrupted when passed through noisy channels. For example, if is a binary signal, it can change with a certain probability,  , to , and it can again be corrupted to produce .
, to , and it can again be corrupted to produce .
Consider the joint probability  . We can express this as:
. We can express this as:
-
 |
|
(16)
|
And if , we get:
-
 |
|
(17)
|
Since  , we can write:
, we can write:
-
 |
|
(18)
|
Thus, we can say that and are conditionally independent given . If we think of as some past event, and as some future event, then the past and future events are independent if we know the present event . Note that this property is good definition of, as well as a useful tool for checking Markovity.
We can rewrite the joint probability  as:
as:
-
 |
|
(19)
|
Therefore, if , then it follows that  .
.
The Data Processing Inequality
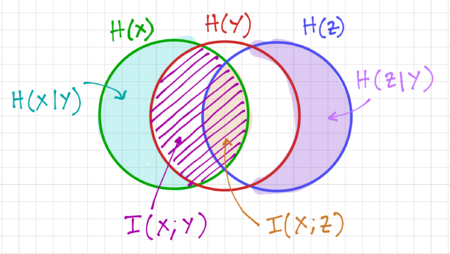
Figure 3: Venn diagram visualization of mutual information in a Markov chain.
Consider three random variables, , , and . The mutual information  can be expressed as:
can be expressed as:
-
 |
|
(20)
|
If , i.e. , , and form a Markov chain, then is conditionally independent of given , resulting in  . Thus,
. Thus,
-
 |
|
(21)
|
And since  , we get the expression known as the Data Processing Inequality:
, we get the expression known as the Data Processing Inequality:
-
 |
|
(21)
|
And since is also a Markov chain, then:
-
 |
|
(22)
|
We can visualize this relation using the Venn diagrams in Fig. 3. Note that the equality occurs when  . It should also be evident that
. It should also be evident that  is independent of
is independent of  given , and that .
given , and that .
Essentially, the data processing inequality implies that no amount of processing or clever manipulation of data can improve inference. Stated in another way, no clever transformation of the received code can give more information about the sent code . This implies that:
- We will loose information when we process information (downside).
- In some cases, the equality still holds even if we discard something (upside). This motivates our exploration of the concept of sufficient statistics.
Sufficient Statistics
Given a family of distributions  indexed by a parameter
indexed by a parameter  . If is a sample from
. If is a sample from  , and
, and  is any statistic, then we get the Markov chain:
is any statistic, then we get the Markov chain:
-
 |
|
(23)
|
From the data processing inequality, we get:
-
 |
|
(24)
|
We say that a statistic is sufficient for if it has all the information contained in about . Mathematically, this means:
-
 |
|
(25)
|
Or equivalently:
-
 |
|
(26)
|
That is, once we know , the remaining randomness in does not depend on .
Fano's Inequality
Consider a communication system, where we transmit , and receive the corrupted version . If we try to infer from , there is always a possibility that we will make a mistake. If  is our estimate of , then
is our estimate of , then  is a Markov chain. We then define the probability of error as:
is a Markov chain. We then define the probability of error as:
-
 |
|
(27)
|
Let us define the error random variable,  , as:
, as:
-
 |
|
(28)
|
We then get  . Using the entropy chain rule:
. Using the entropy chain rule:
-
 |
|
(29)
|
Then the conditional entropy  is:
is:
-
 |
|
(30)
|
Let us look at these terms one by one. If we know and , then there is no uncertainty in the value of , thus:
-
 |
|
(31)
|
Recall that conditioning reduces the uncertainty:
-
 |
|
(32)
|
We can expand  as:
as:
-
 |
|
(33)
|
Note that given  , i.e. there is no error, then there is no uncertainty in given , giving us
, i.e. there is no error, then there is no uncertainty in given , giving us  . And once again, we know conditioning reduces uncertainty, giving us
. And once again, we know conditioning reduces uncertainty, giving us  . Thus, recognizing that
. Thus, recognizing that  and
and  , we get:
, we get:
-
 |
|
(34)
|
If both and have symbols in the alphabet  , then applying the Gibbs inequality, we get
, then applying the Gibbs inequality, we get  , where
, where  is the number of symbols in . This gives us:
is the number of symbols in . This gives us:
-
 |
|
(35)
|
Combining these individual results, we can then write Eq. 30 as:
-
 |
|
(36)
|
Since is a Markov chain, as seen in Figs. 3 and 4, we get Fano's Inequality:
-
 |
|
(37)
|
We can then express the error probability in terms of  :
:
-
Wikimedia Error

Error

|
|
(38)
|
Recall that:
-
Wikimedia Error
Error

|
|
(39)
|
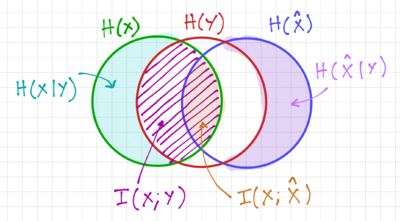
Figure 4: A Venn diagram visualizing
.
We can further recognize that for
Wikimedia Error
Error
 , or equivalently when
, or equivalently when  , we know that is not equal to the actual value of , thus reducing the possible values of from to
, we know that is not equal to the actual value of , thus reducing the possible values of from to  , thus:
, thus:
-
Wikimedia Error
Error

|
|
(40)
|
This allows us to write Eq. 38 as:
-
Wikimedia Error
Error

|
|
(41)
|
And since
Wikimedia Error
Error
 , we get:
, we get:
-
Wikimedia Error
Error

|
|
(42)
|
Thus, Fano's inequality leads to a lower bound on the probability of error, for any decoding function  , and it depends on the mutual information
, and it depends on the mutual information  , or how much information about is contained in , and the size of the alphabet . Thus, to reduce the lower bound of
, or how much information about is contained in , and the size of the alphabet . Thus, to reduce the lower bound of  , we should minimize , or equivalently maximize , as expected.
, we should minimize , or equivalently maximize , as expected.
161-A4.1 Activity A4.1 The Data Processing Inequality and Fano's Inequality -- This activity introduces the concept of information loss and the error probabilities associated with entropy and mutual information.
Sources
- Yao Xie's lecture on Data Processing Inequality.



