A First Look at Shannon's Communication Theory
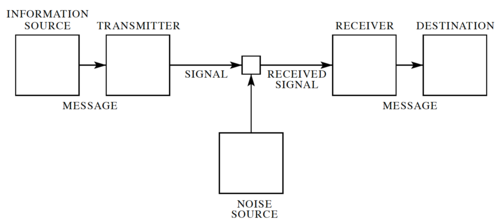
Figure 1: A general communication system
[1].
In his landmark 1948 paper[1], Claude Shannon developed a general model for communication systems, as well as a framework for analyzing these systems. The model has three components: (1) the sender or source, (2) the channel, and (3) the receiver or sink. The model also includes the transmitter that encodes the message into a signal, the receiver, for decoding the signal back into a message, as well the noise of the channel, as shown in Fig. 1.
In Shannon's discrete model, the source provides a stream of symbols from a finite alphabet,  , which are then encoded. The code is sent through the channel, which could be corrupted by noise, and when the code reaches the other end, it is decoded by the receiver, and then the sink extracts information from the steam of symbols.
, which are then encoded. The code is sent through the channel, which could be corrupted by noise, and when the code reaches the other end, it is decoded by the receiver, and then the sink extracts information from the steam of symbols.
Note that sending information in space, e.g. from here to there is equivalent sending information in time, e.g. from now to then. Thus, Shannon's theory applies to both information transmission and information storage.
Shannon's Noiseless Coding Theorem
One very important question to ask is: "How efficiently can we encode the information that we want to send through the channel?" To answer this, let us assume: (1) the channel is noiseless, and (2) the receiver can accurately decode the symbols transmitted through the channel. First, let us define a few things.
A code is defined as a mapping from a source alphabet to a code alphabet. The process of transforming a source message into a coded message is coding or encoding. The encoded message may be referred to as an encoding of the source message. The algorithm which constructs the mapping and uses it to transform the source message is called the encoder. The decoder performs the inverse operation, restoring the coded message to its original form.
A code is distinct if each codeword is distinguishable from every other, i.e. the mapping from source messages to codewords is one-to-one. A distinct code is uniquely decodable (UD) if every codeword is identifiable when immersed in a sequence of codewords. A uniquely decodable code is a prefix code (or prefix-free code) if it has the prefix property, which requires that no codeword is a proper prefix of any other codeword. Prefix codes are instantaneously decodable, i.e. they have the desirable property that the coded message can be parsed into codewords without waiting for the end of the message.
The Kraft-McMillan Inequality
Let  be the alphabet of the channel, or in other words, the set of symbols that can be sent through the channel. Thus, encoding the source alphabet
be the alphabet of the channel, or in other words, the set of symbols that can be sent through the channel. Thus, encoding the source alphabet  can be expressed as a function,
can be expressed as a function,  , where
, where  is the set of all possible finite strings of symbols (or codewords) from
is the set of all possible finite strings of symbols (or codewords) from  .
.
Let  where
where  , i.e. the length of the string of channel symbols encoding the symbol
, i.e. the length of the string of channel symbols encoding the symbol  .
.
A code with lengths  is uniquely decodable if and only if:
is uniquely decodable if and only if:
-
 |
|
(1)
|
The proof of the Kraft-McMillan Inequality is interesting since it starts with evaluating  :
:
-
 |
|
(2)
|
Let  . Thus, the minimum value of
. Thus, the minimum value of  is
is  , when all the codewords are 1 bit long, and the maximum is
, when all the codewords are 1 bit long, and the maximum is  , when all the codewords have the maximum length. We can then write:
, when all the codewords have the maximum length. We can then write:
-
 |
|
(3)
|
Where  is the number of combinations of codewords that have a combined length of
is the number of combinations of codewords that have a combined length of  . Note that the number of distinct codewords of length is
. Note that the number of distinct codewords of length is  . If this code is uniquely decodable, then each sequence can represent one and only one sequence of codewords. Therefore, the number of possible combinations of codewords whose combined length is cannot be greater than , or:
. If this code is uniquely decodable, then each sequence can represent one and only one sequence of codewords. Therefore, the number of possible combinations of codewords whose combined length is cannot be greater than , or:
-
 |
|
(4)
|
We can then write:
-
 |
|
(5)
|
Thus, we can conclude that  since if this were not true, would exceed
since if this were not true, would exceed  for large .
for large .
Entropy and Coding
Let  be equal to:
be equal to:
-
 |
|
(6)
|
We call the set of numbers pseudo-probabilities since  for all
for all  , and
, and
-
 |
|
(7)
|
If  is the probability of observing
is the probability of observing  in the data stream, then we can apply the Gibbs Inequality to get:
in the data stream, then we can apply the Gibbs Inequality to get:
-
 |
|
(8)
|
Rewriting, we get:
-
 |
|
(9)
|
Note that the left hand term is the entropy of the source,  and for , we get:
and for , we get:
-
 |
|
(10)
|
If we define the average length of codewords,  , and rewriting:
, and rewriting:
-
 |
|
(11)
|
In other words, the entropy of the source gives us a lower bound on the average code length for any uniquely decodable symbol-by-symbol encoding of the source message. For binary encoding, where  , we arrive at:
, we arrive at:
-
 |
|
(12)
|
Shannon went beyond this and showed that this bound holds even if we group symbols together into "words" before doing our encoding. The generalized form of this inequality is called Shannon's Noiseless Coding Theorem.
Shannon's Theorem
In general, the channel is itself can add noise. This means that the channel itself serves as an additional layer of uncertainty to our transmissions. Consider a channel with input symbols , and output symbols  . Note that the input and output alphabets do not need to have the same number of symbols. Given the noise in the channel, if we observe the output symbol
. Note that the input and output alphabets do not need to have the same number of symbols. Given the noise in the channel, if we observe the output symbol  , we are not sure which was the input symbol. We can then characterize the channel as a set of probabilities
, we are not sure which was the input symbol. We can then characterize the channel as a set of probabilities  . Let us consider the information we get from observing a symbol .
. Let us consider the information we get from observing a symbol .
Mutual Information
Given a probability model of the source, we have an a priori estimate  that symbol will be sent next. Upon observing , we can revise our estimate to
that symbol will be sent next. Upon observing , we can revise our estimate to  . The change in information, or mutual information, is given by:
. The change in information, or mutual information, is given by:
-
 |
|
(13)
|
Let's look at a few properties of mutual information. Expressing the equation above in terms of  :
:
-
 |
|
(14)
|
Thus, we can say:
-
 |
|
(15)
|
This is expected since, after observing , the amount of uncertainty is reduced, i.e. we know a bit more about . From Bayes' Theorem, we have the property:
-
 |
|
(16)
|
Note that if and are independent, where  and
and  , then:
, then:
-
 |
|
(17)
|
Channel Capacity
We can get the average mutual information over all the input symbols as:
-
 |
|
(18)
|
Similarly, for all the output symbols:
-
 |
|
(19)
|
For both input and output symbols, we get:
-
Shannon's Theory for Analog Channels
Kullback-Leibler Information Measure
Sources
- Tom Carter's notes on Information Theory
- Dan Hirschberg's notes on Data Compression
References
- ↑ 1.0 1.1 C. E. Shannon, A Mathematical Theory of Communication, The Bell System Technical Journal, Vol. 27, pp. 379–423, 623–656, July, October, 1948. (pdf)
