Welcome to CoE 161 / CoE 197!
Since we are offering this class remotely, there will be many changes to our normal course delivery:
- There will be no face-to-face lecture classes. All the material will be made available via this site.
- There will be more emphasis on student-centric activities, e.g. analysis, design, and simulations. Thus, you will be mostly "learning by doing". In this context, we will set aside an hour every week for consultations and questions via video-conferencing.
- Grades will be based on the submitted deliverables from the activities. Though we will not be very strict regarding the deadlines, it is a good idea to keep up with the class schedule and avoid cramming later in the semester.
Please remember that this semester is very different from those before, and please make sure you inform me if you have any issues or difficulties regarding the class. Also, keep in mind that you will need to pay a bit more attention to your time management as it will play a critical role during the course of the semester.
Let's get started!
Measuring Complexity
For any system we are studying, designing, or building, an interesting and important question is usually: "How complex is this system?" or "How complex should this system be?". In general, we want to be able to compare two systems, and be able to say that one system is more complex than the other. In this case, having a numerical metric would be very convenient.
Possible ways of measuring complexity (obviously not a complete list!):
- Human observation, thus making any kind of rating subjective.
- Complexity based on the number of parts, components, or distinct elements. However, this depends on the definition of what is a "part". This is dependent on the observer's scale, from functional components down to atoms at the extreme case, as shown in Fig. 1.
- Number of dimensions. This is sometimes hard to measure, e.g. degrees of freedom, etc.
- Number of parameters controlling the system.
- The minimal description needed. However, we need to figure out which language we need to use.
- Information content. We then need to figure out how to define and measure information.
- Minimum generator or constructor (to build the system). We need to define what tools and methods we need to use to build the system.
- Minimum energy and/or time to construct the system. However, some systems evolve with time, so defining the beginning and end points can be difficult.
All of these measures are associated with a model of the system in question. Thus observers could use different models, and therefore come up with different notions of the complexity of the said system. We do not expect to come up with a single universal measure of complexity, but we can explore a framework that is optimal for (a) a particular observer, (b) a particular context, and (c) a particular purpose. Let us focus on the measures related to how unexpected an observation is, an approach known as Information Theory.
Some of the ideas and concepts that follow are based on basic probability ideas. You can review them here: Probability Review I.
The Basics of Information Theory
We want to create a metric for measuring the information we get from observing the occurrence of an event that has a probability  . Let us ignore all other features of the event, except whether the event occurred or not. We can then think of the event as seeing if a symbol, whose probability of occurring is , appears. Thus, our definition of information is in terms of the probability .
. Let us ignore all other features of the event, except whether the event occurred or not. We can then think of the event as seeing if a symbol, whose probability of occurring is , appears. Thus, our definition of information is in terms of the probability .
An Axiomatic Approach
Let us define our information measure as  . We want to have several properties:
. We want to have several properties:
| Axiom
|
Implied Property
|
|
Information is a non-negative quantity.
|

|
|
If an event has a  , then we get no information from the occurrence of that event. , then we get no information from the occurrence of that event.
|

|
|
If two independent events occur, then the information we get from observing the two events is the sum of the two 'informations'.
|

|
|
is a continuous and monotonic function of the probability .
|
|
Using these properties, we can then derive the following expressions:
-
 |
|
(1)
|
Thus, by induction:
-
 |
|
(2)
|
We can then write  , or equivalently:
, or equivalently:
-
 |
|
(3)
|
In general, we get:
-
 |
|
(4)
|
Since is continuous, and for  and
and  for a real number
for a real number  , we get:
, we get:
-
 |
|
(5)
|
From this, and by inspection, we can express , for some base  as:
as:
-
 |
|
(5)
|
Note that:
-
 |
|
(6)
|
Thus, we can easily change the base of the logarithm, and the resulting information measure are differ by just a multiplicative constant, and have the following units:
| b
|
Units
|
| 2
|
bits (from binary)
|
| 3
|
trits (from trinary)
|

|
nats (from natural logarithm)
|
| 10
|
Hartleys
|
By default, and unless specified, we will be using  , so when we write
, so when we write  , we mean
, we mean  .
.
A Simple Example
If we flip a fair coin, we will get two possible events:  , with probabilities
, with probabilities  . Thus, a one coin flip gives us
. Thus, a one coin flip gives us  bit of information, regardless of the result (
bit of information, regardless of the result ( or
or  ).
).
If we flip the coin  times, or equivalently, if we flip coins at the same time, the amount of information (in bits) that we would get is equal to:
times, or equivalently, if we flip coins at the same time, the amount of information (in bits) that we would get is equal to:
-
 |
|
(7)
|
Enumerating the sequence of 16 flips would give us  , or using a 1 for and 0 for , we would get 1101011011011011. Notice that fair coin flips gives us bits of information, and requires a binary word that is digits long to describe.
, or using a 1 for and 0 for , we would get 1101011011011011. Notice that fair coin flips gives us bits of information, and requires a binary word that is digits long to describe.
Introducing Entropy
Consider a source generating a stream of symbols. If there are distinct symbols,  , and the source emits these symbols with probabilities
, and the source emits these symbols with probabilities  respectively. Let us assume that the symbols are emitted independently, e.g. the emitted symbol does not depend on past symbols.
respectively. Let us assume that the symbols are emitted independently, e.g. the emitted symbol does not depend on past symbols.
If we observe the symbol  , we get
, we get  bits of information from that particular observation.
bits of information from that particular observation.
For  observations, the symbol would occur approximately
observations, the symbol would occur approximately  times. Therefore, if we have independent observations, the total information,
times. Therefore, if we have independent observations, the total information,  , that we will get is:
, that we will get is:
-
 |
|
(8)
|
The average information that we get per symbol that we observe would then be equal to:
-
 |
|
(9)
|
Note that since  , we will define
, we will define  when
when  .
.
The Definition of Entropy
Given a discrete probability distribution  , the entropy of the distribution
, the entropy of the distribution  is:
is:
-
 |
|
(10)
|
For a continuous probability distribution,  , entropy is defined as:
, entropy is defined as:
-
 |
|
(11)
|
This definition was introduced by Claude Shannon in his landmark 1948 paper[1]. For more information on the life of Claude Shannon, you can read this article[2], or watch this documentary film[3].
Alternative Definition of Entropy
For a discrete probability distribution the expected value of an associated discrete set  is given by:
is given by:
-
 |
|
(12)
|
Also, for a continuous probability distribution, , and an associated function  :
:
-
 |
|
(13)
|
Hence, for  , or
, or  , we can see that:
, we can see that:
-
 |
|
(14)
|
Thus, we can think of entropy of a probability distribution as the expected value of the information of the distribution.
The Gibbs Inequality
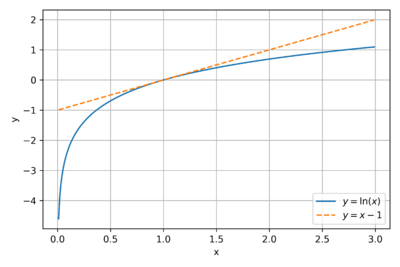
Figure 2: The plot of

and

.
Consider the natural logarithm function,  . The slope of the the line tangent to at any point
. The slope of the the line tangent to at any point  is equal to
is equal to  . Thus, at
. Thus, at  , the equation of the tangent line is , as seen in Fig. 2. Since is concave down, and for
, the equation of the tangent line is , as seen in Fig. 2. Since is concave down, and for  , we get the following inequality:
, we get the following inequality:
-
 |
|
(15)
|
The equality occurs when .
For two probability distributions, and  , and using eq. 15, we get the Gibbs Inequality:
, and using eq. 15, we get the Gibbs Inequality:
-
 |
|
(16)
|
This time, the equality occurs when  for all
for all  . Though we derived the inequality for base , it is straightforward to show that the inequality holds for any base.
. Though we derived the inequality for base , it is straightforward to show that the inequality holds for any base.
Let's use the Gibb Inequality to find the probability distribution that maximizes the entropy. For a probability distribution, :
-
 |
|
(17)
|
Sources
References
- ↑ C. E. Shannon, A Mathematical Theory of Communication, The Bell System Technical Journal, Vol. 27, pp. 379–423, 623–656, July, October, 1948. (pdf)
- ↑ John Horgan, Claude Shannon: Tinkerer, Prankster, and Father of Information Theory, IEEE Spectrum, 2016 (link)
- ↑ The Bit Player (2018) IMDB link

