|
|
| Line 185: |
Line 185: |
| | # The mutual information, <math>I\left(A;B\right)</math>. | | # The mutual information, <math>I\left(A;B\right)</math>. |
| | # The channel capacity, <math>C</math> and show that <math>C=1-H\left(p\right)</math> where <math>H\left(p\right)=p\log_2 \tfrac {1}{p} + \left(1-p\right)\log_2 \tfrac{1}{1-p}</math>. | | # The channel capacity, <math>C</math> and show that <math>C=1-H\left(p\right)</math> where <math>H\left(p\right)=p\log_2 \tfrac {1}{p} + \left(1-p\right)\log_2 \tfrac{1}{1-p}</math>. |
| | + | |
| | + | === Report Guide === |
| | + | In addition to your calculations, include a short explanation of your procedure in obtaining the channel capacity from the your expression for mutual information. Also, comment on the behavior of the channel capacity as <math>p</math> is varied. Is this the behavior you expect? Send your reports via email before you start Module 4. |
| | | | |
| | == Sources == | | == Sources == |
| | * Yao Xie's [https://www2.isye.gatech.edu/~yxie77/ece587/Lecture2.pdf slides] on Entropy and Mutual Information | | * Yao Xie's [https://www2.isye.gatech.edu/~yxie77/ece587/Lecture2.pdf slides] on Entropy and Mutual Information |
- Activity: Mutual Information and Channel Capacity
- Instructions: In this activity, you are tasked to
- Walk through the examples.
- Calculate the channel capacity of different channel models.
- Should you have any questions, clarifications, or issues, please contact your instructor as soon as possible.
Example 1: Mutual Information
Given the following joint probabilities:
Table 1:  : Blood Type,
: Blood Type,  : Chance for Skin Cancer
: Chance for Skin Cancer
|
|
A
|
B
|
AB
|
O
|
| Very Low
|
1/8
|
1/16
|
1/32
|
1/32
|
| Low
|
1/16
|
1/8
|
1/32
|
1/32
|
| Medium
|
1/16
|
1/16
|
1/16
|
1/16
|
| High
|
1/4
|
0
|
0
|
0
|
To get the entropies of and , we need to calculate the marginal probabilities:
-
 |
|
(1)
|
-
 |
|
(2)
|
And since:
-
 |
|
(3)
|
We get:
-
 |
|
(4)
|
-
 |
|
(5)
|
Calculating the conditional entropies using:
-
 |
|
(6)
|
-
 |
|
(7)
|
Note that  . Calculating the mutual information, we get:
. Calculating the mutual information, we get:
-
 |
|
(8)
|
Or equivalently:
-
 |
|
(9)
|
Let us try to understand what this means:
- If we only consider , we have the a priori probabilities,
 for each blood type, and we can calculate the entropy,
for each blood type, and we can calculate the entropy,  , i.e. the expected value of the information we get when we observe the results of the blood test.
, i.e. the expected value of the information we get when we observe the results of the blood test.
- Will our expectations change if we do not have access to the blood test, but instead, we get to access (1) the person's susceptibility to skin cancer, and (2) the joint probabilities in Table 1? Since we are given more information, we expect one of the following:
- The uncertainty to be equal to the original uncertainty if and are independent, since
 , thus
, thus  .
.
- A reduction in the uncertainty equal to
 , due to the additional information given by
, due to the additional information given by  .
.
- If and are perfectly correlated, we reduce the uncertainty to zero since
 and
and  .
.
Example 2: A Noiseless Binary Channel

Figure 1: Channel model for a noiseless binary channel.
Consider transmitting information over a noiseless binary channel shown in Fig. 1. The input,  has a priori probabilities
has a priori probabilities  and
and  , and the output is
, and the output is  . Calculating the output probabilities:
. Calculating the output probabilities:
-
 |
|
(10)
|
-
 |
|
(11)
|
Thus, the entropy at the output is:
-
 |
|
(12)
|
The conditional entropy,  is then:
is then:
-
 |
|
(13)
|
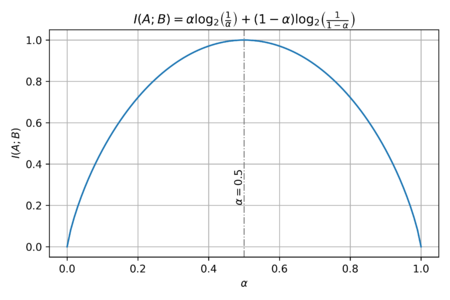
Figure 2: The mutual information as a function of

.
Which is expected since  and
and  are perfectly correlated, and there is no uncertainty in once is given. Thus, the mutual information is:
are perfectly correlated, and there is no uncertainty in once is given. Thus, the mutual information is:
-
 |
|
(14)
|
The plot of the mutual information as a function of is shown in Fig. 2. To get the channel capacity, we get the maximum  over all . Thus, we can take the derivative of the mutual information and set it equal to zero, to find the optimal . And noting that
over all . Thus, we can take the derivative of the mutual information and set it equal to zero, to find the optimal . And noting that  , we get:
, we get:
-
 |
|
(15)
|
Thus, we can get  , as expected from Fig. 2. Therefore the channel capacity is:
, as expected from Fig. 2. Therefore the channel capacity is:
-
 |
|
(16)
|
As expected, in a noiseless binary channel, we can transmit a maximum of 1 bit of information per channel use.
Example 3: A Noisy Channel with Non-Overlapping Outputs

Figure 3: A noisy channel with non-overlapping outputs.
Consider the channel shown in Fig. 3. The input, has a priori probabilities and , and in this case, the output is  . Once again, we can calculate the output probabilities:
. Once again, we can calculate the output probabilities:
-
 |
|
(17)
|
-
 |
|
(18)
|
-
 |
|
(19)
|
-
 |
|
(20)
|
Note that the terms that evaluate to zero have already been omitted. The entropy at the output is then:
-
 |
|
(21)
|
Calculating the conditional entropy:
-
 |
|
(22)
|
This allows us to calculate the mutual information:
-
 |
|
(23)
|
Which once again leads to a channel capacity,  bit per channel use, at . This reinforces our intuition that as long as each output symbol is determined by only one input symbol, i.e. no overlaps, we can infer which input symbol was transmitted when we know the output symbol even in the presence of noise.
bit per channel use, at . This reinforces our intuition that as long as each output symbol is determined by only one input symbol, i.e. no overlaps, we can infer which input symbol was transmitted when we know the output symbol even in the presence of noise.
Activity: The Binary Symmetric Channel (BSC)

Figure 4: The binary symmetric channel.
A more realistic channel model is the Binary Symmetric Channel shown in Fig. 4. For this channel, there is a probability  that if a 0 is transmitted, the channel corrupts it into a 1. The same is true for transmitting a 1, there is a probability that the output is converted to a 0.
that if a 0 is transmitted, the channel corrupts it into a 1. The same is true for transmitting a 1, there is a probability that the output is converted to a 0.
Given the input, has a priori probabilities and , calculate the following in terms of and :
- The output probabilities
 and
and  .
.
- The entropy at the output,
 .
.
- The conditional entropy, .
- The mutual information, .
- The channel capacity,
 and show that
and show that  where
where  .
.
Report Guide
In addition to your calculations, include a short explanation of your procedure in obtaining the channel capacity from the your expression for mutual information. Also, comment on the behavior of the channel capacity as is varied. Is this the behavior you expect? Send your reports via email before you start Module 4.
Sources
- Yao Xie's slides on Entropy and Mutual Information



